

- 6일차 공부
- 전날 수업 내용 복습
- DB 격리수준 공부(Read Uncommitted, Read Committed, Repeatable Read, Serializable)
- JOIN 공부 및 실습 (INNER JOIN, LEFT OUTER JOIN)
- UNION 공부 및 실습
- 서브쿼리 공부
- GROUP BY (HAVING절) 공부 및 실습(집계함수, GROUP BY)
- 프로그래머스 SQL 코딩테스트 실습(5문제)
SQL 심화 수업을 시작했다. JOIN, UNION, GROUP BY 등 실무에서든 코딩테스트에서든 필수적인 문법들을 배우고 실습했다. 문법이나 코딩테스트 문제에 대한 이해는 됐지만 헷갈리고 아직까지 어려운 부분도 있다. SQL은 JAVA에 비하면 쉬운편이고 무조건 잡고 가야하는 부분이라고 알고있기 때문에 헷갈리지 않을 정도만이라도 공부해야겠다는 생각이다.
내일도 화이팅..!!
- 6일차 공부 메모
5일차 수업 복습 진행
Spring을 사용하면 기본적으로는 사용하는 DB 설정을 기본으로 따라감
- repeatable read 기본
- 낙관적 락(문제안생길거야), 비관적 락(문제가 무조건 생길거야)
- 비관적락 - 공유락(read 허용), 배타적 락(select for update)
- 배타적 락에서 생길 수 있는 문제 = 데드락(교착상태)
- Maria DB에서는 교착상태가 일정 시간 지속되면 rollback을 시킨다.
- 서비스를 구성할 때 교착상태가 걸리지 않도록 순방향으로 설계하거나
- 겹치지 않게 구성하
- 비관적락 - 공유락(read 허용), 배타적 락(select for update)
- 낙관적 락 - 락을 걸지 않고 프로그램으로 해결도 가능
- DB 격리수준
- DB 동시성 문제를 해결하기 위한 격리수준
- Read Uncommitted
- 즉, 데이터가 변경되었다면, 커밋되지 않았다 하더라도 읽을 수 있도록 하는 격리수준
- dirty read 발생 가능
- Read Committed
- 다른 트랜잭션이 커밋된 데이터만 읽을 수 있는 격리수준.
- 다만, 나의 트랜잭션에 여러 select 문이 있을 경우에, 그 사이에 다른 트랜잭션에서 update 또는 insert 등을 발생시키고 commit하게 될시 phantom read(insert 관련 문제) 또는 non-repeatable-read(update 관련 문제) 발생가능
- Repeatable Read
- 한 번 읽은 데이터는 같은 트랜잭션 내에서는 항상 같은 값을 갖도록 하는 격리수준 나의 트랜잭션에서 먼저 read하는 동안 다른 트랜잭션에서는 변경,추가 하더라도 같은 read값을 보장하는 것. -> Non-Repeatable Read과 Phantom read를 해결
- repeatable read를 하더라도 두가지 문제가 발생할 가능성 존재
- 나의 트랜잭션이 read하는 동안 타 트랜잭션에서 update하게 되면 read해온 값이 달라지는 문제 발생 -> select for update로 타 트랜잭션의 업데이트를 대기하게 한 후 update ⇒ 배타적 락
- 그러나, select for update도 두 다른 트랜잭션이 동시에 read하는 것은 가능하여 lost update 문제 가능성 존재 ex)상품주문의 최종 수량이 1개 -> transaction에 read && update가 있을때 -> 내 tran에서 1 read -> 타 트랜잭션이 1 read -> 내 tran에서 0으로 update -> 타 tran에서 0으로 update -> 최종 수량에 오류 발생
- Serializable (최고격리수준) - 상업용에서는 사용안함 사용자 경험이 느리다.
- 동시에 실행되는 여러 트랜잭션들을 순차적으로 실행한 것과 같은 결과를 보장 -> 즉 데이터베이스 차원에서 동시에 특정 데이터에 접근하는 것을 차단
- 여러 테이블에서 가져온 레코드를 조합하여 하나의 테이블이나 결과 집합으로 표현
- 크게는 INNER JOIN, OUTER JOIN으로 구분
- INNER JOIN
- 두 테이블 사이에 지정된 조건에 맞는 레코드만을 반환. 양쪽 테이블에 모두 해당 조건에 맞는 값이 있어야 결과에 포함
- ex)author와 post를 inner조인하면 글을 작성한적이 있는 author와 해당 author가 작성한 post정보를 결합하여 조회
- 가장 일반적인 형태
- OUTER JOIN
- 하나의 테이블을 기준으로 모든 레코드와 그에 JOIN된 다른 테이블의 일치하는 레코드를 반환
- 왼쪽테이블이 기준이면 LEFT (OUTER) JOIN, 오른쪽 기준이면 RIGHT (OUTER) JOIN
- LEFT JOIN이 더 일반적으로 많이 사용되는 JOIN
- ex)author의 테이블은 일단 다 조회하고 author가 작성한 글정보를 조회하고 싶다면, author테이블에 post테이블을 left join
- INNER JOIN
- INNER JOIN
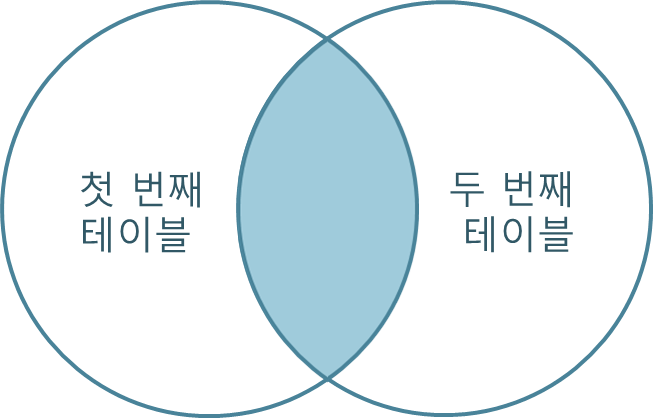
- tableA의 ID와 tableB의 a_id가 일치하는 ON 조건을 만족하는 데이터만 JOIN
- SELECT * FROM tableA INNER JOIN tableB ON tableA.ID = tableB.A_ID
- SELECT * FROM tableA AS a INNER JOIN tableB AS b on a.ID = b.a_id;
- 출력결과
- TableA의 모든컬럼 + TableB의 모든컬럼
- 그 중에 ON조건을 만족하는 row만 출력
- LEFT OUTER JOIN

- 문법
- SELECT * FROM tableA a LEFT JOIN tableB b ON a.id = b.a_id
- 출력결과
- TableA의 모든컬럼 + TableB의 모든컬럼
- A테이블 데이터는 row는 모두 출력 B데이터는 ON 조건에 맞는 데이터만 출력
- ON조건에 맞지 않는 B데이터는 null로 출력
- A테이블의 데이터를 기준으로 B테이블의 데이터를 정렬
- JOIN 특이사항
===== JOIN 실습 =====
- -- author 테이블과 post 테이블을 JOIN하여, 글을 작성한 모든 저자의 이름(name)과 해당 글의 제목(title)을 조회 하시오. -- author는 alias a, post는 alias p를 쓰시오 select a.name, p.title from author as a inner join post as p on a.id = p.author_id;
- -- author 테이블을 기준으로 post 테이블과 JOIN하여, 모든 저자의 이름과 해당 저자가 작성한 글의 제목을 조회하시오. -- 글을 작성하지 않은 저자의 경우, 글 제목은 NULL로 표시 select a.name, p.title from author as a left outer join post as p on a.id = p.author_id;
- -- 위 예제와 동일하게 모든 저자의 이름과 해당 저자가 작성한 글의 제목을 조회. 단, 저자의 나이가 25세 이상인 저자만 조회 select a. name, a. age, p.title from author as a left outer join post as p on a.id = p.author_id where a.age > 25;
- UNION
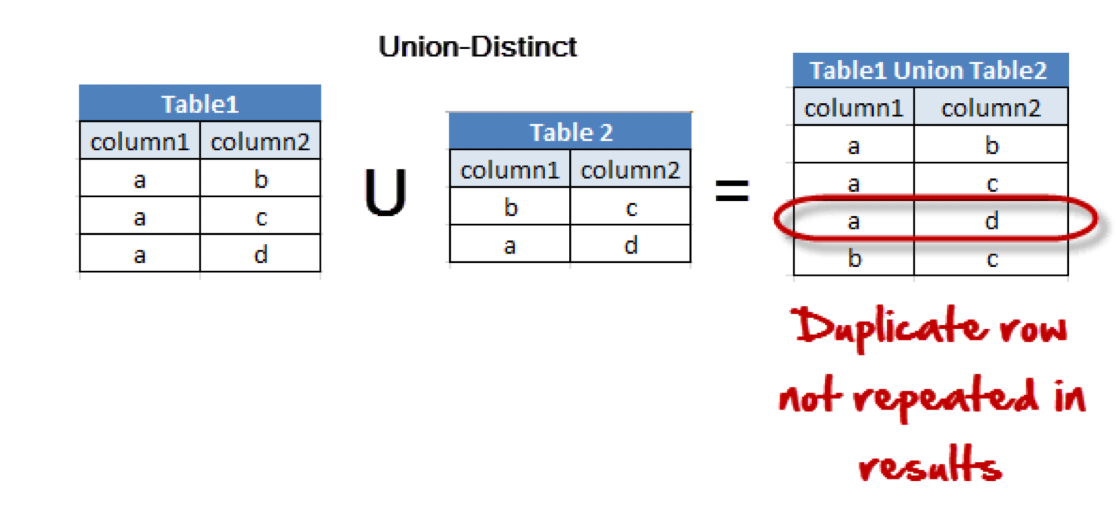
- 여러 개의 SELECT 문의 결과를 하나의 테이블이나 결과 집합으로 표현
- 각각의 SELECT 문으로 선택된 필드의 개수와 타입은 모두 일치해야함
- UNION은 DISTINCT 키워드를 따로 명시하지 않아도 중복되는 레코드를 제거
- 중복되는 레코드까지 모두 출력하고 싶다면 UNION ALL
- UNION - WITH RECURSIVE
- WITH RECURSIVE 키워드는 sql에서 재귀문으로서 자기 자신을 참조하여 반복적으로 데이터를 생성하거나 변형하면서 ~
- 예시)
WITH RECURSIVE number_sequence(HOUR) AS (
SELECT 0
UNION ALL
SELECT HOUR + 1 FROM number_sequence WHERE HOUR < 23
)
select HOUR, 0 as COUNT from number_sequence;
- 서브쿼리
- 서브쿼리(subquery)란 다른 쿼리 내부에 포함되어 있는 SELECT 문을 의미
- JOIN대신 서브쿼리를 써보자
- IN과 NOT IN을 많이 사용
- SELECT * FROM tableA WHERE id IN (SELECT a_id FROM tableB);
- 서브쿼리는 반드시 괄호(())로 감싸져 있어야 한다
- 대부분의 서브쿼리는 join으로 대체가능하고 join을 쓰는것이 성능이 더 좋음
- 단, 매우 복잡한 쿼리는 join으로 대체하는 것이 불가능
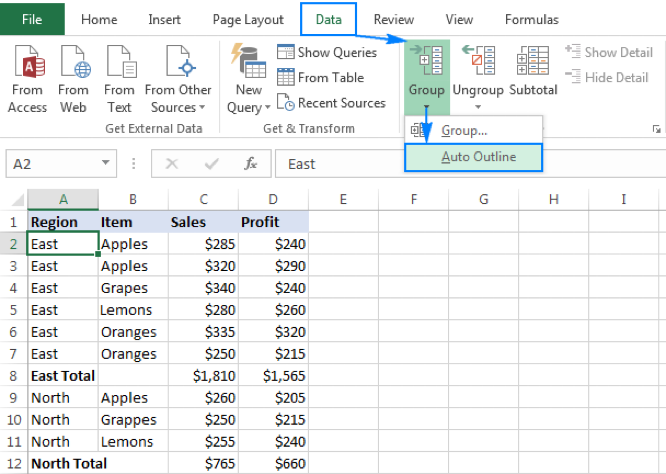
- GROUP BY
- 선택된 레코드의 집합을 특정 값으로 그룹화한 결과 집합
- select 컬럼명 from 테이블명 group by 컬럼
- 사용목적
- 데이터의 값을 집계하기 위해
- 주로 집계 함수와 같이 사용(total sum, average 등)
- 아래 excel의 경우 Region을 group화 시켜 통계값 산출
- 선택된 레코드의 집합을 특정 값으로 그룹화한 결과 집합
- 집계함수
- COUNT() : 행의 개수를 세어줌
- AVG() : 행 안에 있는 값의 평균을 내어줌
- MIN() : 행 안에 있는 값의 최솟값을 반환해줌
- MAX() : 행 안에 있는 값의 최댓값을 반환해줌
- SUM() : 행 안에 있는 값의 합을 내어줌
- 예시)
- select author_id, count(*) from post group by author_id
- author_id로 그룹화한 데이터의 갯수구하는 집계 SQL
- 만약 post마다 원고료가 있었다면, select author_id, sum(price), avg(price) from post group by author_id
- select author_id, count(*) from post group by author_id
- HAVING 절
- HAVING 절은 GROUP BY를 사용하여 그룹화된 후의 데이터에 대한 조건을 설정
- WHERE 절은 데이터를 그룹화하기 전의 개별 레코드에 대한 조건을 설정
- HAVING 절은 주로 집계 함수(COUNT(), SUM(), AVG() 등)와 함께 특정 조건을 만족하는 그룹만을 필터링하고 싶을 때 사용
- select author_id, count(*) as count from post group by author_id having count > 3;
===== 집계함수 실습 =====
- select author_id, count(*), sum(price), avg(price) from post group by author_id;
===== GROUP BY 실습 =====
- select author_id, avg(price) from post where price >= 30000 group by author_id;
- select author_id, avg(price) from post group by author_id having avg(price) >= 30000;
- select author_id, avg(price) from post where price >= 30000 group by author_id having avg(price) >= 30000;
===== 프로그래머스 SQL 코테 실습 =====
입양시각구하기(1)
성분으로 구분한 아이스크림 총 주문량
자동차 종류 별 특정 옵션이 포함된 자동차 수 구하기
재구매가 일어난 상품과 회원 리스트 구하기
입양시각구하기(2)
- 테스트 → 동시에 접속 → tool
- 면접에서 실무와 연결지어서 물어볼 가능성 많음
- JOIN SQL은 완벽하게 할 수 있어야 함
- 셀프조인왜글헤오
'한화시스템 백엔드 SW교육' 카테고리의 다른 글
| 한화시스템 BEYOND 캠프 3기 3주차 회고 (3) | 2023.12.08 |
|---|---|
| 한화시스템 BEYOND 캠프 3기 2주차 회고 (0) | 2023.12.05 |
| 2023.11.20 5일차 회고 (3) | 2023.11.21 |
| 한화시스템 BEYOND 캠프 3기 1주차 회고 (3) | 2023.11.20 |
| 2023.11.17 4일차 회고 (2) | 2023.11.17 |